차세대 대규모 LLM ‘트리-21B’ 오픈소스 공개…‘고정밀 추론’ 강력한 성능
XLDA 기술 적용, 한국어·일본어 등 저자원 언어 효과적 전이 지원
사전학습 기반 자체 개발, ‘AI 기술 주권’ 확보…해외 기술 종속성 탈피

[시사저널e=이창원 기자] LLM(대규모 언어 모델)을 설계·개발해왔던 ‘트릴리온랩스’가 글로벌 경쟁력을 갖춘 이른바 ‘한국형 LLM’을 선보이며 시장에서 새로운 길을 개척하고 있다.
트릴리온랩스는 올해 들어 ‘트리-21B(Tri-21B)’, ‘트릴리온-7B(Trillion-7B-preview)’ 등 LLM 모델을 오픈소스로 공개하고, 이와 같은 서비스 고도화를 지속하며 풀사이즈 LLM 포트폴리오를 구축해나간다는 계획이다.
특히 ‘AI 기술 주권’이 주요 화두로 떠오르고 있는 상황에서 트릴리온랩스의 독자적인 한국형 LLM 모델의 향후 행보가 주목된다.
25일 업계에 따르면, 트릴리온랩스는 최근 차세대 대규모 LLM 트리-21B를 오픈소스로 공개했다. 이번에 공개된 트리-21B는 단순한 텍스트 생성 능력을 넘어 고차원적 언어 이해와 복잡한 문제 해결을 동시에 수행할 수 있도록 설계된 LLM 모델이다.
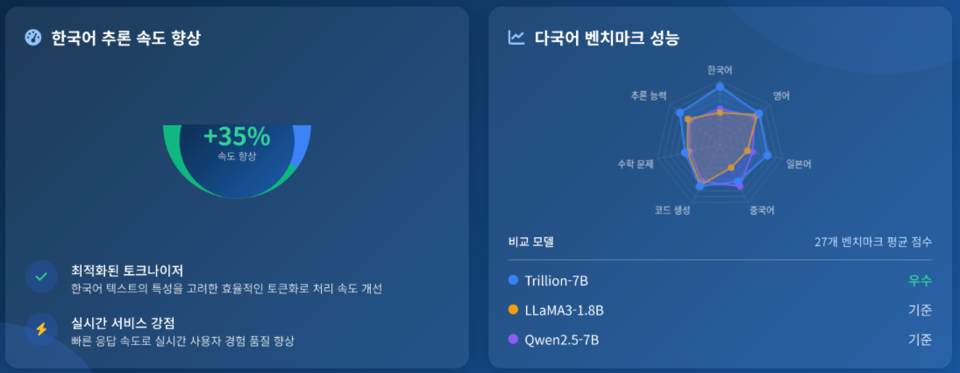
앞서 지난 선공개된 트릴리온-7B 대비 파라미터 수를 3배 이상 확장한 약 210억개 규모로 성능을 대폭 향상시켰다. 또한 1대의 GPU에서도 원활하게 작동할 수 있도록 경량성과 효율성을 강화했다.
트리-21B의 가장 큰 경쟁력은 고정밀 추론이 필요한 작업에서 강력한 성능을 발휘하도록 설계됐다는 점이다. 수학과 코딩 등 단계적 사고가 요구되는 문제에 대해 구조화된 답변을 생성하는 생각사슬(CoT, Chain of Thought)구조를 채택했고, 트릴리온-7B와 마찬가지로 자사의 언어 간 상호학습 시스템(Cross-lingual Document Attention, XLDA) 기술을 적용했다.
XLDA는 영어 기반 지식을 한국, 일본 등 동북아 국가들의 학습 데이터가 부족한 저자원 언어(low-resource languages)로 효과적인 전이가 가능하도록 하는 데이터 학습 방법론이다.
트릴리온랩스는 “(XLDA를 통해) 기존 대비 1/12 수준으로 학습 비용을 대폭 절감하는 혁신을 이뤄냈다”며 “데이터가 부족한 산업 분야에서도 LLM 활용도를 획기적으로 끌어올릴 수 있는 기반을 마련했다는 점에서 의미가 크다”고 설명했다.
실제 트리-21B는 종합지식(MMLU), 한국어 언어 이해(KMMLU), 수학(MATH), 코딩(MBPP Plus) 등 고난도 추론 중심 벤치마크에서 알리바바 ‘Qwen 3’, 메타 ‘LLaMA 3’, 구글 ‘Gemma 3’ 등 글로벌 대표 중형 모델과 견줄만한 성능을 입증하기도 했다.
추론능력 검증(77.93점, CoT적용시 85점), 수학(77.89점), 코딩(75.4점) 등 영역에서 높은 정확도를 보이며 실제 문제 해결 능력에서도 강점을 확인했다.
주요 한국어 벤치마크에서도 한국문화의 이해도를 측정하는 해례(Hae-Rae) 86.62점, 한국어 지식·추론능력 62점(CoT적용시 70점) 등 영역에서 글로벌 모델 대비 월등히 높은 점수를 기록하며 어휘·문맥 이해, 문화적 맥락 반영에서 독보적인 한국어 이해능력을 보였다.
신재민 트릴리온랩스 대표는 “트리-21B는 플라이휠 구조를 통해 70B급 대형 모델의 성능을 21B에 효과적으로 전이해 모델 사이즈와 비용, 성능 간 균형에서 현존하는 가장 이상적인 구조를 구현했다”며 “이번 모델처럼 바닥부터 사전학습으로 개발한 고성능 LLM을 통해 비용 효율성과 성능 개선을 빠르게 달성해 한국 AI 기술력의 완성도를 높이고, 향후 공개될 트리-70B와 함께 풀사이즈 LLM 포트폴리오를 완성해 나가겠다”고 밝혔다.
지난해 8월 설립된 트릴리온랩스가 빠른 속도로 독자적인 LLM 모델을 설계·개발할 수 있게 된 데에는 독특한 개발 방식이 주효했다는 평가가 나온다.
우선 트릴리온랩스는 사전학습 기반 자체 개발(Pre-training, From-scratch) 방식을 통해 처음부터 독자적으로 모델을 설계하고 학습시켜왔다. 이와 같은 개발 방식은 완전한 제어권을 확보함으로써 기업이나 사용자가 원하는 방향으로 모델을 자유롭게 개선할 수 있고, 새로운 지식이나 기능을 효율적으로 추가할 수 있다는 장점이 있다.
또한 오픈소스 모델 기반으로 일부 데이터를 추가 학습시키는 파인튜닝(fine-tuning) 방식의 한계인 기술 지속성과 보안 취약성 문제를 근본적으로 해결하는 동시에 AI 외부 의존도를 줄이고, 자체 기술력을 바탕으로 한 지속가능한 AI 생태계 구축이 가능한 것이 특징이다.
트릴리온랩스는 “자체 모델 개발로 민감한 데이터에 대한 완전한 통제권을 보장함으로써 가격 변동, 정책 변경, 서비스 중단 등 공급망 리스크를 최소화하고, 해외 기술에 대한 종속성을 탈피할 수 있다”며 “고객 가치와 제품 혁신 관점에서도 혁신적인 제품과 차별화된 고객 경험을 창조하기 위해서는 모델 설계 단계 부터의 완전한 기술 자율성이 필수”라고 말했다.
한편, 트릴리온랩스는 ‘네이버 하이퍼클로바 X(7B~60B 모델)’ 사전학습의 핵심 연구자로 참여했던 신 대표를 중심으로 카이스트, 옥스포드, 버클리, 아마존, 네이버 등 국내외 최고 수준의 연구기관·테크 기업 출신 엔지니어·연구원으로 구성된 스타트업 기업이다.
합성 데이터 전문가인 신 대표는 ‘NAACL 2025 Best Paper Award’를 수상한 ‘Prometheus’ 논문 시리즈의 주요 저자이고, 한국형 LLM 개발 성과를 인정받아 ‘NVIDIA GTC 2025’의 소버린 AI의 초청 강연자로 선정되기도 했다.
이와 같은 기술력을 바탕으로 트릴리온랩스는 설립 직후인 지난해 9월 580만 달러(한화 약 90억원) 규모의 Pre-Seed 투자를 유치한 바 있다.